Python(Colab) 파이토치(Pytorch) + 딥러닝 + 포켓문분류
2023. 7. 6. 14:29ㆍ파이썬/머신러닝 및 딥러닝
✔ 데이터셋
train 데이터 - https://www.kaggle.com/datasets/thedagger/pokemon-generation-one
validation 데이터 - https://www.kaggle.com/datasets/hlrhegemony/pokemon-image-dataset
1. 다운로드 하기
import os
import shutil
os.environ['KAGGLE_USERNAME'] = 캐글 아이디
os.environ['KAGGLE_KEY'] = 캐글 고유 키
!kaggle datasets download -d thedagger/pokemon-generation-one
!kaggle datasets download -d hlrhegemony/pokemon-image-dataset

2. 압축해제 하기
!unzip -q pokemon-generation-one.zip
!unzip -q pokemon-image-dataset.zip
3.압축 푼 데이터 폴더 이름 변경
os.rename('images','validation')
os.rename('dataset','train')
#강사님버전
!mv images validation
전처리
train에는 149종 포켓몬이 있고
validation에는 898종 포켓몬이 있다.
따라서 검증 데이터에서 학습 데이터와 겹치는 포켓몬만 분류하기
li1 = list(os.listdir('validation'))
li2 = list(os.listdir('train'))
temp_1 = list()
se1 = list(set(li1) & set(li2))
print(len(se1))
for i in li2:
if i not in se1:
print(i)

데이터 학습 준비
1. 모듈 import 하기
#패키지 로드
#GPU 사용
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
2. gpu 사용 준비 (cpu사용시 cpu / gpu 사용시 cuda라고 출력)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)

3. 방대한 이미지를 한번에 변형 시키기Transforms.Compose
data_transforms = {
'train': transforms.Compose([
transforms. Resize((224,224)),
transforms.RandomAffine(0,shear=10, scale=(0.8,1.2)), #크기 -20% ~ +20% 사이에서 해라
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]),
'validation': transforms.Compose([
transforms. Resize((224,224)),
transforms.ToTensor()
])
}
Resize =(a,b) 이미지 사이즈를 (a X b)사이즈로 변경
RandomHorizontalFlip() = 이미지를 좌우 반전시키기
RandomAffine(0,shear=10,scale=(0.8,1.2)) : 이미지의 모양을 0도로 회전하고, -10~10도 기울게 하고, 사이즈는 80%~120%로 무작위로 변환시켜줘라
ToTensor() = 텐서 객체로 변환해줘라
4. 데이터 셋 만들기
image_datasets = {
'train': datasets.ImageFolder('train',data_transforms['train']),
'validation': datasets.ImageFolder('validation',data_transforms['validation'])
}
해석
torchvision의 dataset를 이용해서 train이라는 데이터셋을 형성하는데, 여기 들어오는 이미지는 data_transforms['train]의 적용을 받은 것을 담는다.
validation도 마찬가지
5. 데이터 로더 만들기
dataloaders = {
'train': DataLoader(
image_datasets['train'],
batch_size=32,
shuffle=True
),
'validation': DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False
)
}
해석
'train'이라는 것은 데이터로더를 만든다
data는 image_dataset['train']
batch_size = 32 (한번에 처리하는 미니 배치 크기)
shuffle = True
6. 이미지 클래스 확인하기
image_datasets['train'].classes
image_datasets['train'].classes[81]

7. 시각화 해보기
imgs, labels = next(iter(dataloaders['train'])) #iter객체 만들기
fig, axes = plt.subplots(4,8,figsize=(20,10))
for img, label, ax in zip(imgs,labels,axes.flatten()):
ax.set_title(label.item())
ax.imshow(img.permute(1,2,0))
ax.axis('off')

모델 준비
1. EfficientNetB4 모델 사용하기
사전 학습된 모델 import 해오기
model = models.efficientnet_b4(weights='IMAGENET1K_V1').to(device)
print(model)
2.파라미터는 수정하지 않고, fc모델만 수정
for param in model.parameters():
param.requires_grad = False #가져온 파라미터를 업데이트 하지 않겠다.
model.classifier = nn.Sequential(
nn.Linear(1792,512),
nn.ReLU(),
nn.Linear(512,149)
).to(device)
print(model)
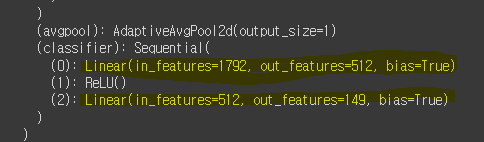
학습하기
# 학습
# 학습: fc 부분만 학습하므로 속도가 빠름
optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)
epochs = 10
for epoch in range(epochs):
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in dataloaders[phase]:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(x_batch)
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss.item()
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
acc= (y_batch == y_pred_index).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc.item()
avg_loss = sum_losses / len(dataloaders[phase])
avg_acc = sum_accs / len(dataloaders[phase])
print(f'{phase:10s}: Epoch {epoch+1:4d}/{epochs}, Loss: {avg_loss:.4f}, Accuracy: {avg_acc:.2f}%')
학습된 모델 저장 및 불러오기
# 학습된 모델 파일 저장
torch.save(model.state_dict(),'model.h5')
#강사님 버전 (모델 다운받아서 쓰기)
model = models.efficientnet_b4(weights='IMAGENET1K_V1').to(device)
model.classifier = nn.Sequential(
nn.Linear(1792,512),
nn.ReLU(),
nn.Linear(512,149)
).to(device)
model.load_state_dict(torch.load('pokemon.h5'))
model.eval()
모델을 초기로 불러와서 fc 모델만 수정하고 기존에 저장한 모델을 불러온다.
모델 검증
1. 검증파일 준비
from PIL import Image
# validation의 이미지 오픈
img1 = Image.open('content/validation/Arbok/0.jpg')
img2 = Image.open('content/validation/Butterfree/3.jpg')
img1_input = data_transforms['validation'](img1)
img2_input = data_transforms['validation'](img2)
print(img1_input.shape)
print(img2_input.shape)
test_batch = torch.stack([img1_input,img2_input])
test_batch = test_batch.to(device)
print(f'{test_batch.shape}')
검증하려고 하는 이미지 파일 2개를 불러온다
transforms으로 모델에 들어갈 수 있게 형식을 맞춘다.
🔴stack을 통해 한줄의 배열로 만든다!!
2. 검증하기
y_pred = model(test_batch)
y_pred
#최적화 (0~1사이)
y_prob = nn.Softmax(1)(y_pred)
y_prob
#강사님 팁
#probs 인덱스가 반환, indices 확률값 상위 3개가 나온다.
probs, indices = torch.topk(y_prob, k=3, axis=-1)
probs = probs.cpu().data.numpy()
indices = indices.cpu().data.numpy()
print(probs)
print(indices)
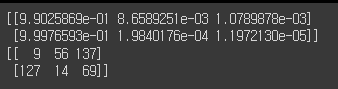
3. 시각화하기
# 화면 띄우기
fig, axes = plt.subplots(1,2,figsize=(12,6))
D
axes[0].set_title('{:.2f}% {},{:.2f}% {},{:.2f}% {}'.format(
probs[0,0]*100, image_datasets['validation'].classes[indices[0,0]], # 1번일 확률
probs[0,1]*100, image_datasets['validation'].classes[indices[0,1]], # 2번일 확률
probs[0,2]*100, image_datasets['validation'].classes[indices[0,2]] # 3번일 확률
))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].set_title('{:.2f}% {},{:.2f}% {},{:.2f}% {}'.format(
probs[1,0]*100, image_datasets['validation'].classes[indices[1,0]], # 1번일 확률
probs[1,1]*100, image_datasets['validation'].classes[indices[1,1]], # 2번일 확률
probs[1,2]*100, image_datasets['validation'].classes[indices[1,2]] # 3번일 확률
))
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()

728x90
'파이썬 > 머신러닝 및 딥러닝' 카테고리의 다른 글
| [Python] BriaAI / Image-Segement(이미지 분리) 누끼따기 (0) | 2024.05.28 |
|---|---|
| [TTS] TTS 설치 중 Visual studio 버전 에러 (0) | 2024.05.21 |
| Python(Colab) 파이토치(Pytorch) + 딥러닝 + 전이학습 (Alien vs predator) (0) | 2023.06.24 |
| Python(Colab) 파이토치(Pytorch) + 딥러닝 + CNN + 손글씨 데이터 (0) | 2023.06.21 |
| Python(Colab) 파이토치(Pytorch) + 딥러닝 + CNN 사용해보기 (0) | 2023.06.21 |