Python(Colab) 파이토치(Pytorch) + 딥러닝 + 전이학습 (Alien vs predator)
2023. 6. 24. 16:12ㆍ파이썬/머신러닝 및 딥러닝
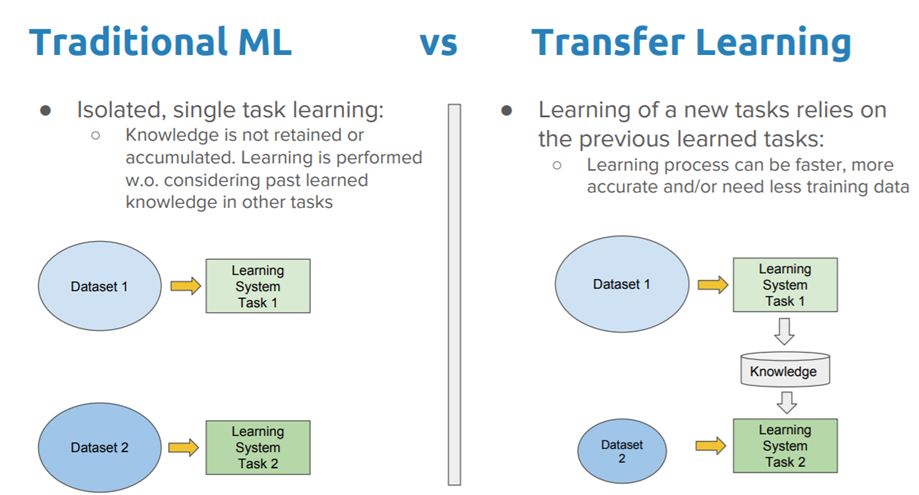
✔️전이학습
* 하나의 작업을 위해 훈련된 모델을 유사 작업 수행 모델의 시작점으로 활용하는 딥러닝 접근법
* 신경망은 처음부터 새로 학습하는 것보다, 전이 학습을 통해 업데이트하고 재 학습하는 편이 더 빠르고, 간편하다
* 전이 학습은 여러 응용 분야 중에서도 특히 검출, 영상 인식, 음성 인식, 검색 분야에 많이 사용
✔️ 고려해야할 점
* 데이터의 크기: 모델 크기의 중요성은 모델을 배포할 위치와 방법에 따라 달라진다.
* 정확도: 재 훈련전의 모델 성능은 어느 정도인지 확인이 필요
* 예측속도: 하드웨어 및 배치 크기와 같은 다른 딥러닝 요소는 물론, 선택된 모델의 구조와 크기에 따라 달라진다.
파이토치에서 제공되는 사전학습 모델들이 많이 존재한다.

kaggle 데이터 (에일리언 vs 프레데터)로 예제 해보기
1. 데이터셋 다운 받기
import os
import shutil
os.environ['KAGGLE_USERNAME'] = #username
os.environ['KAGGLE_KEY'] = #token
!kaggle datasets download -d pmigdal/alien-vs-predator-images
!unzip -q alien-vs-predator-images.zip
✔️kaggle 토큰 받는법
kaggle 로그인 -> Setting -> API항목 -> Create New Token -> json 다운로드 -> 편집기로 열어서 확인
2.기초 설정
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
3. 이미지 증강 기법(Image Augmentation) 사용하기
원본 데이터(이미지)를 조작해서 원본보다는 크고 작은 변화를 가진 이미지를 생성
장점) 모델 성능↑ / 과적합 방지
data_transforms = {
'train': transforms.Compose([
transforms. Resize((224,224)),
transforms.RandomAffine(0,shear=10, scale=(0.8,1.2)), #크기 -20% ~ +20% 사이에서 해라
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]),
'validation': transforms.Compose([
transforms. Resize((224,224)),
transforms.ToTensor()
])
}
해석
1. data_transforms라는 변수를 dict형태로 만든다.
2. 'train'이라는 key에 torchvision의 transforms.Compose함수를 사용한다
transforms.Compose(): 여러개의 함수를 한꺼번에 적용시켜주는 것
2-1. transforms.Resize(): 해당 가로 세로 사이즈 변경
2-2 transforms.RandomAffine(각도,): 랜덤으로 아핀변환을 해준다.
2-3. transforms.RandomHorizontalFlip(): 좌우반전
2-4. transforms.ToTensor(): 텐서형으로 변경

4. datasets.ImageFolder 사용해서 데이터 나누기
def target_transforms(x):
return torch.FloatTensor([x])
image_datasets = {
'train': datasets.ImageFolder('data/train/',data_transforms['train'],target_transform=target_transforms),
'validation': datasets.ImageFolder('data/validation',data_transforms['validation'],target_transform=target_transforms)
}
dataloaders = {
'train': DataLoader(
image_datasets['train'],
batch_size=32,
shuffle=True
),
'validation': DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False
)
}
✔️ datasets.ImageFolder(파일경로,변환방법(함수),변환후 타입)
- 폴더 구조로 이루어진 이미지 데이터셋을 다루기 위해 사용한다.
- 특징은 폴더 안에 분류별로 폴더 정리가 되어있어야만 가능하다.
- 상위디렉토리 안에 하위 디렉토리는 각각의 클래스로 정의된다.
예시) 그림폴더 -> 장미(장미1.jpg /장미2.jpg/장미3.jpg )
해석
1.image_datasets라는 딕셔너리에 train이란 키에는 datasets.ImageFolder라는 함수로 data/train안에 파일들을 데이터셋을 형성하는데, 그 데이터들은 data_transforms['train']의 함수를 적용받고, 그 후 target_transforms에 적용된 형태로 변경된다.
2. validation도 마찬가지
3. 그 이후 가공된 데이터들의 데이터로더를 만들어준다.
5. 가공된 데이터의 개수 파악
print(len(image_datasets['train']),len(image_datasets['validation']))

print(len(dataloaders['train']))
print(len(dataloaders['validation']))

해석
1번 코드는 데이터 로더로 적용전 데이터의 크기로 train:694개 / validation은 200개이다.
2번코드로 데이터 로더를 적용하면 데이터 크기는 traind은 22개 / validation은 7개이다.
이유) batch_size가 32이기 때문에 694/32 =21.6875이기때문에 22개로 된 것이다.
6. 학습 데이터 시각화로 확인하기
imgs, labels = next(iter(dataloaders['train'])) #iter객체 만들기
fig, axes = plt.subplots(4,8,figsize=(20,10))
for img, label, ax in zip(imgs,labels,axes.flatten()):
ax.set_title(label.item())
ax.imshow(img.permute(1,2,0))
ax.axis('off')
해석
1.imgs,labels라는 변수로 학습데이터를 반복가능객체로 변환후 next함수를 통해 호출시 각각 요소를 반환하게 만든다.
2. fig,axes 변수 = subplots(전체표가로4, 전체표세로8,전체표사이즈20,10) 만든다. (subplots는 return이 2개이다)
3. 시각화

모델 셋팅(resnet50)
pytorchvision.models는 사전 학습된 모델을 사용할 수 있는 것이다.
weights는 이미지넷이라는 곳에서 사전 학습을 해오라는 뜻
model = models.resnet50(weights='IMAGENET1K_V1').to(device)
print(model)

모델 셋팅
for param in model.parameters():
param.requires_grad = False #가져온 파라미터를 업데이트 하지 않겠다.
model.fc = nn.Sequential(
nn.Linear(2048,128),
nn.ReLU(),
nn.Linear(128,1),
nn.Sigmoid()
).to(device)
print(model)
해석
1번째 resnet50에서 가져온 파라미터를 업데이트하지 않겠다는 뜻
2번째
선형회귀 (input 2048, output 128개)로 하겠다.
활성화 함수(Relu)를 통해 비선형 측정
선형회귀 (input 128, output1)
시그모이드함수로 0~1사이로 변환
✔️왜 처음 선형회귀 모델의 input이 2048일까?
print(model)시 출력 fc layer의 input이기때문이다.
사전 학습된 모델이기때문에 처음엔 해당으로 맞춰준다.(out은 바껴도 상관없다)

학습시키기
# 학습: fc 부분만 학습하므로 속도가 빠름
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
epochs = 10
for epoch in range(epochs):
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in dataloaders[phase]:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(x_batch)
loss = nn.BCELoss()(y_pred, y_batch)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss.item()
y_bool = (y_pred >= 0.5).float()
acc = (y_batch == y_bool).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc.item()
avg_loss = sum_losses / len(dataloaders[phase])
avg_acc = sum_accs / len(dataloaders[phase])
print(f'{phase:10s}: Epoch {epoch+1:4d}/{epochs}, Loss: {avg_loss:.4f}, Accuracy: {avg_acc:.2f}%')

해석
1번 학습 후 바로 검증하기 위해
2번 총 손실율과 총 정확도를 계산하기 위해
3번 문제와 정답을 학습후 y_pred로 예측값 확인
4번 손실율 구할 함수 정의 (BCELoss(): 문제의 정답이 두개이기떄문)
5번 만약 학습 중이라면 최적화를 0으로 만들고 / 손실율에 대한 가중치를 계산 / 가중치를 업데이트 한다
6번 총 손실율에 loss의 값(sclar)값을 더한다
7번 50% 이상 확률이면 1로 변환하기
8번 y_batch(정답)과 예측이 맞다면 1 아니면 0으로 변환 후 그 모든 숫자의 합으로 정확도를 구한다.
9번 총 손실율 과 정확도를 구한다









테스트해보기
img1 = Image.open('data/validation/alien/32.jpg')
img2 = Image.open('data/validation/predator/45.jpg')
img1_input = data_transforms['validation'](img1)
img2_input = data_transforms['validation'](img2)
print(img1_input.shape)
print(img2_input.shape)
#이미지 2개를 하나로 결합해줌
test_batch = torch.stack([img1_input,img2_input])
test_batch = test_batch.to(device)
print(f'{test_batch.shape}')

========================================================================
y_pred = model(test_batch)
print(y_pred)
print(y_pred[0,0])
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].set_title(f'{(1-y_pred[0, 0]) * 100:.2f}% Alien, {y_pred[0, 0] * 100:.2f}% Predator')
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].set_title(f'{(1-y_pred[1, 0]) * 100:.2f}% Alien, {y_pred[1, 0] * 100:.2f}% Predator')
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()

해석
1. 테스트할 이미지를 불러온다
2. 이미지를 텐서형으로 변경한다.
3. 이미지 2개를 1개의 형태로 묶어준다.(모델 아웃풋이 1개로 설정되어있기때문에)
4. 시각화로 확인한다.
모델 저장하기
torch.save(model.state_dict(),'model.h5')
728x90
'파이썬 > 머신러닝 및 딥러닝' 카테고리의 다른 글
| [TTS] TTS 설치 중 Visual studio 버전 에러 (0) | 2024.05.21 |
|---|---|
| Python(Colab) 파이토치(Pytorch) + 딥러닝 + 포켓문분류 (0) | 2023.07.06 |
| Python(Colab) 파이토치(Pytorch) + 딥러닝 + CNN + 손글씨 데이터 (0) | 2023.06.21 |
| Python(Colab) 파이토치(Pytorch) + 딥러닝 + CNN 사용해보기 (0) | 2023.06.21 |
| Python(Colab) 파이토치(Pytorch) + 딥러닝 + CNN기초(이미지) (2) | 2023.06.21 |