Python(Colab) lightGBM
2023. 6. 17. 15:51ㆍ파이썬/머신러닝 및 딥러닝
✔️ lightGBM
- LGBM(Leaf)이라고도 부른다.
- 트리기반 학습 알고리즘
- gradient boosting 방식 프레임 워크
✔️GBM이란?
✔️하이퍼 파라미터
1) n_estimators
반복 수행할 트리의 개수를 설정하는 파라미터 (Default 100)
값을 크게 지정하면, 학습시간도 오래걸리며, 과적합 가능성↑
2) max_depth
트리의 최대 깊이 (Default -1)
3)num_leaves
전체 트리의 잎 개수 (Default 31)
4) learning_rate
학습율 (그래프의 이동 간격 Default 0.1)
✔️특징
장점
학습하는데 걸리는 시간이 적다
메모리 사용량이 상대적으로 적은 편이다.
단점
적은 데이터셋을 사용할 경우 과적합 가능성이 매우 높다. (최소 만 개 이상 사용해야함.)

데이터로 실습
1. 기초설정
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
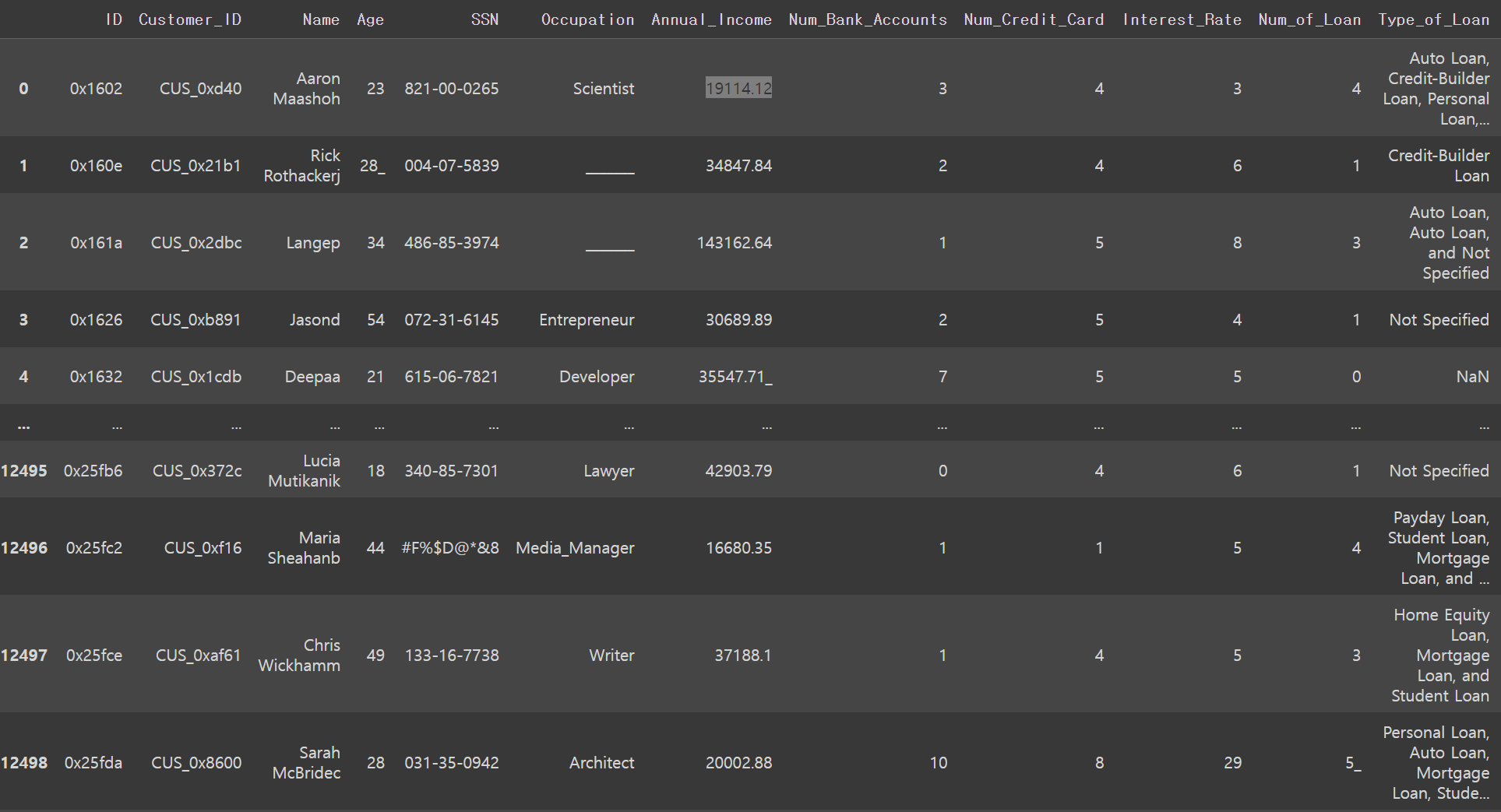
credit_df = pd.read_csv('/content/drive/MyDrive/KDT-1/머신러닝과 딥러닝/credit.csv')
credit_df
2. 상관관계가 없는 데이터 열 지우기
개인정보는 상관관계가 없을 것이니 지우기
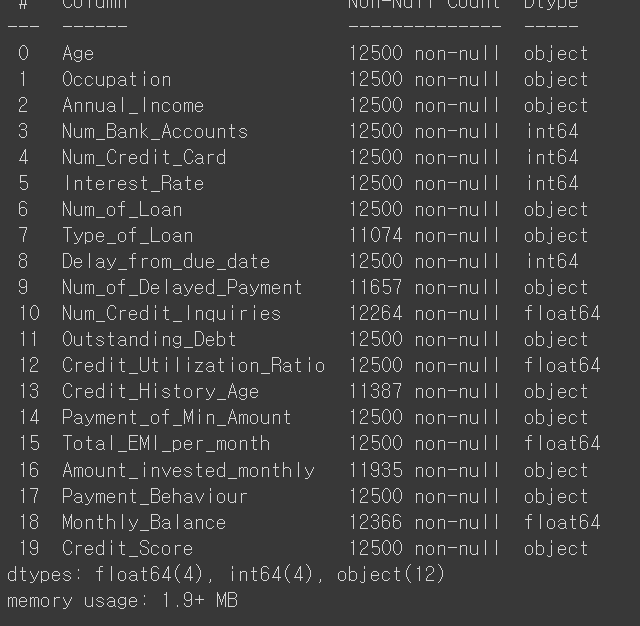
credit_df.drop(['ID','Customer_ID','Name','SSN'],axis=1,inplace=True)
credit_df.info()
3. 타입이 object인 컬럼 확인하고 처리하기
1) 'Credit_Score': 신용도
credit_df['Credit_Score'].value_counts()
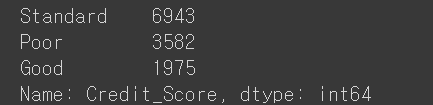
credit_df['Credit_Score'] = credit_df['Credit_Score'].replace({'Poor':0 , 'Standard':1, 'Good':2})
종류가 별로 되지 않아서 0,1,2로 처리
for i in credit_df.columns:
if credit_df[i].dtype == 'O':
print(i)

for i in ['Age', 'Annual_Income', 'Num_of_Loan', 'Num_of_Delayed_Payment', 'Outstanding_Debt', 'Amount_invested_monthly']:
credit_df[i] = pd.to_numeric(credit_df[i].str.replace('_', ''))
object 컬럼 데이터의 _가 있어서 처리하고 숫자타입으로 변경
# Credit_History_Age의 데이터를 개월로 변경
# 22 Years and 1 Months -> 22 * 12 + 1
credit_df['Credit_History_Age'] = credit_df['Credit_History_Age'].str.replace(' Months', '')
credit_df['Credit_History_Age'] = pd.to_numeric(credit_df['Credit_History_Age'].str.split(' Years and ', expand=True)[0])*12 + pd.to_numeric(credit_df['Credit_History_Age'].str.split(' Years and ', expand=True)[1])
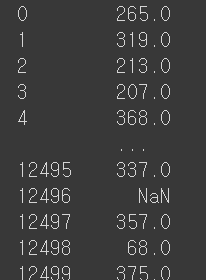
str.split(expand=True)
데이터를 각각 다른 컬럼으로 분류해준다.
4. 상관관계가 있어 보이는 컬럼 찾기 (독립변수)
1) 'Payment_of_Min_Amount' : 리볼빙 여부
sns.barplot(x='Payment_of_Min_Amount',y='Credit_Score',data=credit_df)
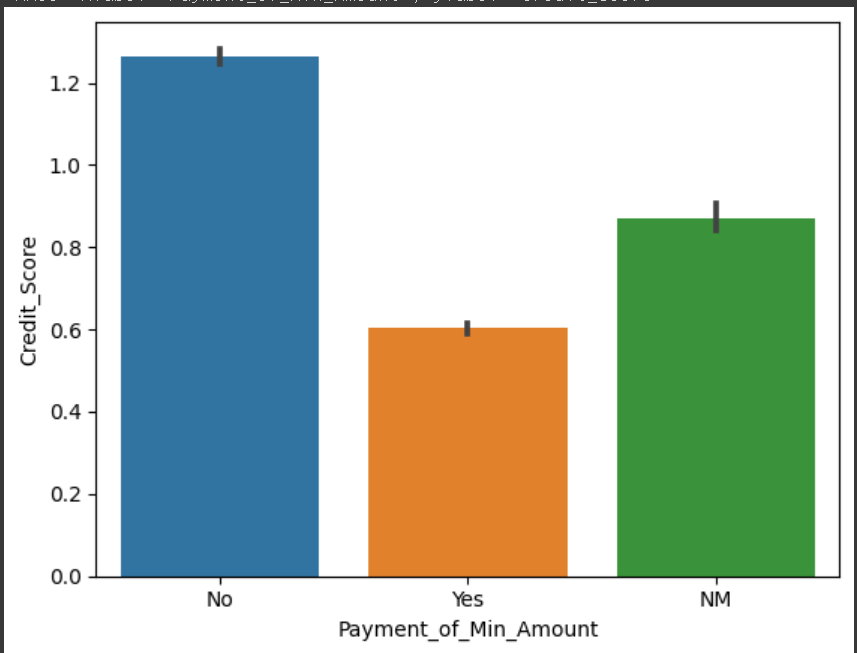
2) 'Occupation': 직업
plt.figure(figsize=(20,5))
sns.barplot(x='Occupation',y='Credit_Score',data=credit_df)
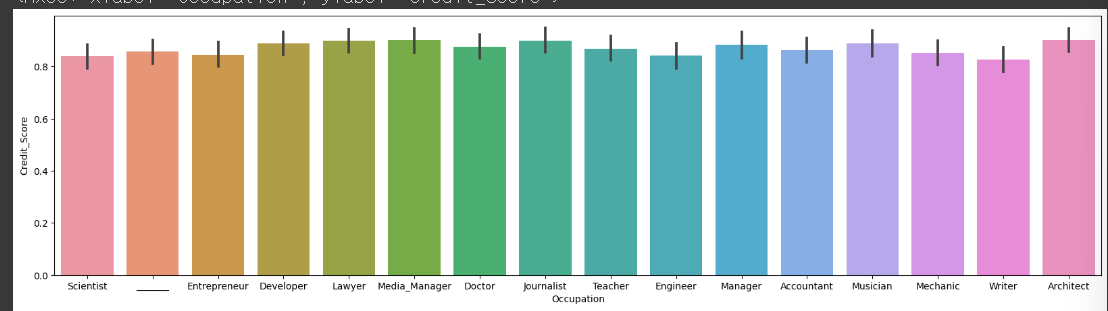
3) 상관계수 보기
heatmap과 corr()사용하기
plt.figure(figsize=(12,12))
sns.heatmap(credit_df.corr(),cmap='coolwarm',vmin=-1,vmax=1,annot=True)
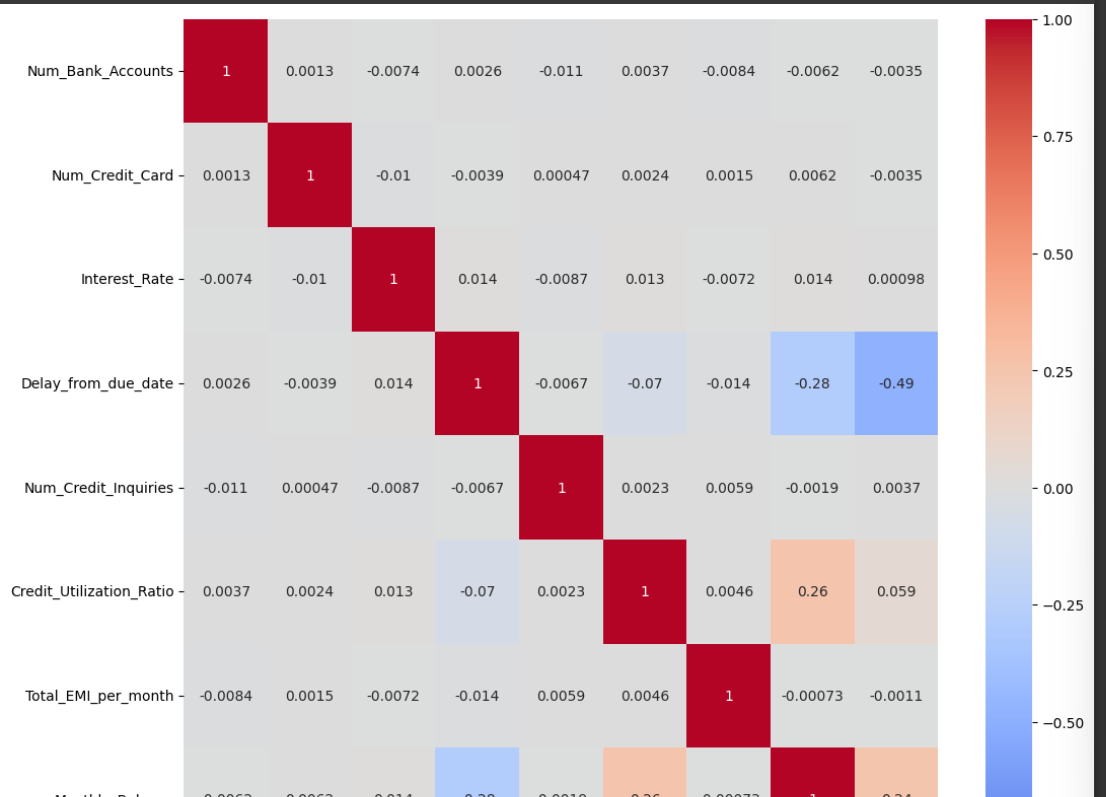
컬럼별 상관관계를 보기위해 heatmap을 사용한다 (데이터.corr()) 필수 !
4) Age: 나이 / 데이터 이상한 값 처리 (ex 나이가 110살 이상 혹은 나이가 -500살)
sns.boxplot(y=credit_df['Age'])
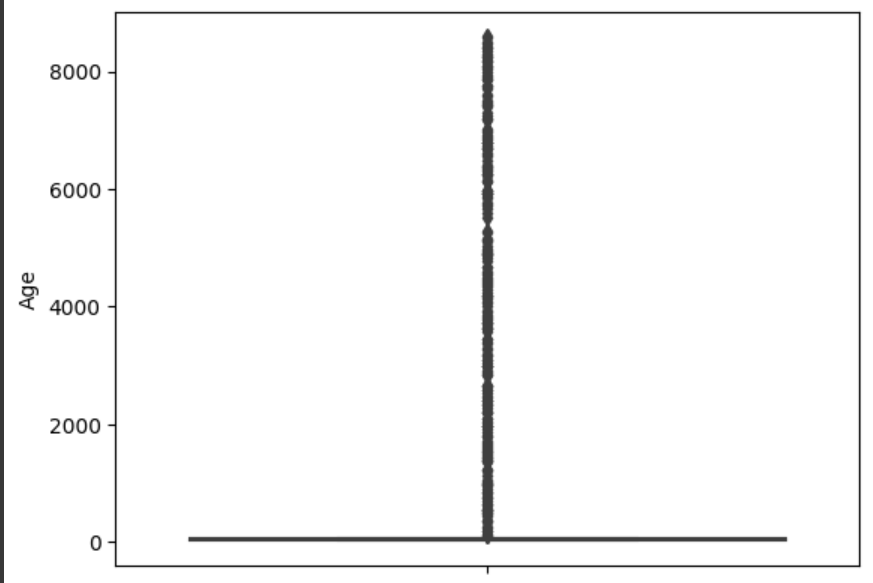
credit_df = credit_df[credit_df['Age'] >= 0]
credit_df = credit_df[credit_df['Age'] < 120]
5) Num_Bank_Accounts: 통장 갯수 / 너무 많은 사람은 제거
len(credit_df[credit_df['Num_Bank_Accounts'] > 10]) / len(credit_df)

credit_df = credit_df[credit_df['Num_Bank_Accounts']<=10]
6) Num_Credit_Card: 신용카드 갯수 / 너무 많은 사람은 제거
credit_df = credit_df[credit_df['Num_Credit_Card']<=10]
7) Num_of_Loan : 대출 건수 / 40이상은 제거
credit_df = credit_df[(credit_df['Num_of_Loan']<=10) & (credit_df['Num_of_Loan']>= 0)]
8) Type of Loan : 대출 방법 / 데이터가 섞여서 들어가서 중복 된 것이 많다. / 처리
기존데이터
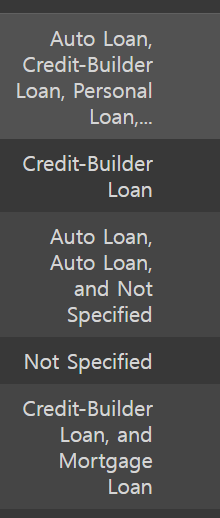
#and를 없애기
credit_df['Type_of_Loan'] = credit_df['Type_of_Loan'].str.replace('and ','')
# NaN 값이 1109개여서 No Loan으로 대체
credit_df['Type_of_Loan'] = credit_df['Type_of_Loan'].fillna('No Loan')
type_list = set(credit_df['Type_of_Loan'].str.split(', ').sum())
type_list
for i in type_list:
credit_df[i] = credit_df['Type_of_Loan'].apply(lambda x : 1 if i in x else 0)
5. 학습데이터 검증데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(credit_df.drop('Credit_Score',axis=1),credit_df['Credit_Score'], test_size=0.2,random_state=12345)
ligthGBM 적용시키기
from lightgbm import LGBMClassifier
base_model = LGBMClassifier(random_state=12345)
base_model.fit(X_train,y_train)
pred1 = base_model.predict(X_test)
평가지표로 확인해보기
# 여러가지 평가지표
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report,roc_auc_score
accuracy_score(y_test,pred1)

confusion_matrix(y_test,pred1)

print(classification_report(y_test,pred1))
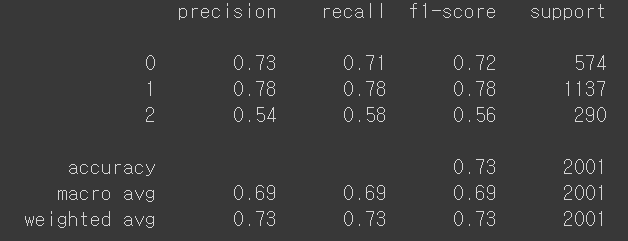
✔️ roc_auc_score에는 OvO와 OvR이 있는데 이것은 분류가 3가지이기때문에 OVR
# 3가지 분류이기때문에 OvR사용할 예정
roc_auc_score(y_test,proba1,multi_class='ovr')

✔️ 최적의 파라미터 찾기 2번째
RandomSearchCV()
- 분류기를 결정하고 해당 분류기의 최적의 하이퍼 파라미터를 찾기 위한 방법
방법)
튜닝하고 싶은 파라미터를 지정
파라미터 값의 범위를 지정
n_iter 값을 설정 (검색 횟수)
내가 테스트 해보고 싶은 하이퍼 파라미터 설정 후 학습시키기
parameter= {
'n_estimators':[100,300,500],
'max_depth': [-1,30,50,100],
'num_leaves': [5,10,20,50],
'learning_rate':[0.01,0.05,0.1,0.5]
}
from sklearn.model_selection import RandomizedSearchCV
lgbm = LGBMClassifier()
# 빈 모델 / 위에 설정한 파라미터들 / 반복 횟수 / 데이터 고정
rand_lgbm = RandomizedSearchCV(lgbm,parameter, n_iter=30,random_state=12345)
rand_lgbm.fit(X_train,y_train)
# 결과 확인하기
rand_lgbm.cv_results_
최적의 하이퍼 파라미터 확인
rand_lgbm.best_params_

최적의 파라미터 적용
728x90
'파이썬 > 머신러닝 및 딥러닝' 카테고리의 다른 글
| Python(Colab) KMeans + 실루엣 기법 / 클러스터링 (0) | 2023.06.18 |
|---|---|
| Python(Colab) KMeans / 클러스터링 (0) | 2023.06.17 |
| Python(Colab) 랜덤 포레스트 (Random Forest) (0) | 2023.06.16 |
| Python(Colab) 서포트 백터 머신 (Support Vector Machine) (0) | 2023.06.15 |
| Python(Colab) 로지스틱 회귀(Logistic Regression) (0) | 2023.06.14 |