Python Pandas 기초
2023. 6. 8. 15:32ㆍ파이썬
http://bigdata.dongguk.ac.kr/lectures/Python/_book/pandas.html#pandas-dataframe
5 장 Pandas | 파이썬 프로그래밍 기초
Pandas 데이터 처리와 분석을 위한 라이브러리 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있음 대용량의 데이터들을 처리하는데 매우 편리 pandas 자료구조 Series: 1차원 DataFrame: 2차원 Panel:
bigdata.dongguk.ac.kr
사용 Tool : Google Colab
기초 설정
! pip install pandas
import pandas as pd
1-1 Series와 DataFrame
* 2차원 표 데이터를 데이터 프레임 / 데이터 :values / 표의 행: index / 표의 열: colum
* 1차원 표 데이터는 Series / values index로 이루어짐
* 데이터프레임과 시리즈의 value는 넘파이의 ndarray기반이다
데이터 프레임 만들어보기
data1 = [[67,93,91],
[66,92,90],
[65,91,89],
[64,90,88],
[63,89,87]]
idx = ['김사과','반하나','오렌지','이메론','배에리' ] 인덱스로 사용할 예정
col = ['국어','영어','수학' ] 컬럼으로 사용할 예정
데이터 프레임 만들기(data1 즉 value만 가지고)
pd.DataFrame(data1)

데이터프레임 만들기 (data1 = value 와 idx = 인덱스)
pd.DataFrame(data1,idx)

데이터프레임 만들기 (data1 = value 와 idx = 인덱스 col = 컬럼)
df1 = pd.DataFrame(data1,idx,col)

딕셔너리를 이용한 데이터 프레임 만들기
dic1 ={
'국어':[67,66,65,64,63],
"영어":[93,92,91,90,89],
"수학":[91,90,89,88,87],
}
idx = ['김사과','반하나','오렌지','이메론','배에리' ]
df2=pd.DataFrame(data=dic1,index=idx)
df2

시리즈 만들기
data2 = [67,66,65,64,63]
pd.Series(data2)

가공하기
인덱스 넣기
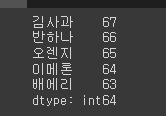
se1 = pd.Series(data2,idx)
print(se1)
Method 및 관련 함수
M1. 데이터프레임.values: 데이터 프레임의 value값들을 반환한다(ndarray로 나온다)

M2. 데이터프레임.index: 데이터 프레임의 모든 index 값을 보여준다

M3. 데이터프레임.columns: 데이터 프레임의 모든 column 값을 보여준다

M4. 데이터프레임.shape: 데이터 프레임의 행렬을 간단하게 표현해준다

Df1. 데이터프레임.info(): 데이터 프레임의 정보들을 간단하게 보여준다

Df2. 데이터프레임.describe(): 데이터 프레임의 통계정보를 출력해준다 (조건: 숫자타입)

Df3. 데이터프레임.head(n): 데이터 프레임의 상위 n개 행을 출력

Df4. 데이터프레임.tail(n): 데이터 프레임의 하위 n개 행을 출력

Df4. 데이터프레임.sort_index(): index를 기준으로 오름차순 정렬
#index로 오름차순 정렬
df.sort_index() ##기본값
#index로 내림차순 정렬
df.sort_index(ascending=False)
#value의 따른 오름차순 정렬
df.sort_values('height') ##NaN값은 맨 밑으로 깔림
df.sort_values(by='height')
#값에 따른 내림차순 정렬
df.sort_values(by='height',ascending=False)
#NaN을 가장 위로 올리기 (na_position default = last)
df.sort_values(by='height', na_position='first')
판다스 함수1. pd.read_csv(파일경로 혹은 다운받을수 있는 URL, 인코딩방식)
pd.read_csv('korean-idol.csv')
pd.read_csv('/content/drive/MyDrive/KDT-1/데이터분석/korean-idol.csv')
#다운받을수 있는 URL
실습 및 예시
기본데이터

Height를 가지고 1차 정렬 후 blackpink를 값을 가지고 2차 정렬 (오름차순)
df.sort_values(['height','blackpink'], ascending=[False,True],na_position='first')
df.sort_values(by=['height','blackpink'], ascending=[False,True],na_position='first')
728x90
'파이썬' 카테고리의 다른 글
| Python(Colab) 데이터프레임 결측값(isna,isnull,notnull,fillna,dropna) (0) | 2023.06.08 |
|---|---|
| Python(Colab) 데이터프레임 인덱싱(loc,iloc,boolean) (0) | 2023.06.08 |
| Python Numpy 모듈 (0) | 2023.05.29 |
| Day14_MySQL_Python 로그인 프로그램 작성 (0) | 2023.03.22 |
| Day14_MYSQL_Python 회원가입 프로그램을 만들어보자 (0) | 2023.03.22 |