Python(Colab) 파이토치(Pytorch) + 논리 회귀 (와인품종 예측)
2023. 6. 20. 22:36ㆍ파이썬/머신러닝 및 딥러닝
목표: 13개 성분을 분석하여 어떤 품종에 와인인지 예측하자
1. 데이터셋 : sklearn.datasets.load_wine (학습데이터 80%, 테스트 데이터 20%)
from sklearn.datasets import load_wine
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
x_data,y_data = load_wine(return_X_y=True,as_frame=True) #한번에 데이터 프레임
x_data= torch.FloatTensor(x_data.values)
y_data= torch.LongTensor(y_data.values)
2. 종속변수 원핫인코딩 시키기 (계산값이 0~1사이로 나오게 하기위해)
y_one_hot = nn.functional.one_hot(y_data, num_classes=3).float()
3. 학습 데이터 검증데이터 나누기
x_train, x_test, y_train, y_test = train_test_split(x_data,y_one_hot,test_size=0.2,random_state=10)
print(x_train.shape, x_test.shape)
print(y_train.shape, y_test.shape)

4. 모델 셋팅 후 학습
model = nn.Sequential(
nn.Linear(13,3)
)
optimizer = optim.SGD(model.parameters(),lr=0.1)
epochs =1000
for epoch in range(epochs+1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred,y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
y_train_index = torch.argmax(y_train,axis=1)
accuracy = (y_train_index == y_pred_index).float().sum() / len(y_train)*100
print(f'Epoch { epoch:4d}/{epochs} Loss: {loss:.6f} Accuracy: {accuracy:.2f}%')

정확도가 너무 낮다 다른 경사 하강법을 사용해보자.
✔️경사 하강법 종류
1. 배치 경사 하강법 (기본)
2. 확률적 경사 하강법 : 배치 경사도의 메모리소비와 시간이 길다는 단점을 개선한 방법
3. 미니 배치 경사 하강법 : Batch 사이즈가 1 or 전체 데이터 개수도 아닌 경우



경사 하강법 기술 적용한 기술
✔️ 확률적 경사 하강법 (SGD)
- 매개변수 값을 조정시 전체 데이터가 아니라, 랜덤으로 선택한 한개의 데이터 에 대해서만 계산
✔️모멘텀(Momentum)
- 관성이라는 물리학 법칙을 응용한 방법
✔️아다그리드(Adagrad)
- 모든 매개변수에 동일한 학습률을 적용한 것이 비효율적이다라는 생각에서 만들어진 학습방법
✔️ 아담(Adam)
- 모멘텀 + 아다그리드
- 우리는 이것을 사용해볼 예정


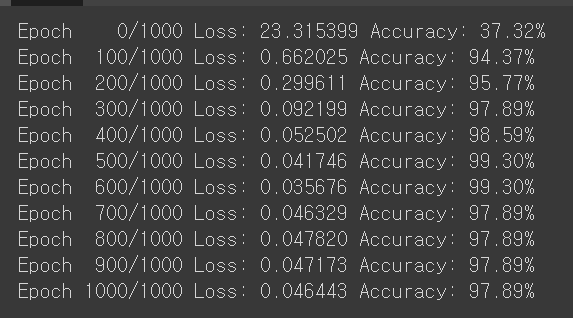
### 아담으로 바꿔서 해보기
model = nn.Sequential(
nn.Linear(13,3)
)
optimizer = optim.Adam(model.parameters(),lr=0.1)
epochs =1000
for epoch in range(epochs+1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred,y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
y_train_index = torch.argmax(y_train,axis=1)
accuracy = (y_train_index == y_pred_index).float().sum() / len(y_train)*100
print(f'Epoch { epoch:4d}/{epochs} Loss: {loss:.6f} Accuracy: {accuracy:.2f}%')
테스트해보기
y_pred = model(x_test)
y_prob = nn.Softmax(1)(y_pred)
y_prob[:5]

print(f'0번 품종일 확률 {y_prob[0][0]:.2f}')
print(f'1번 품종일 확률 {y_prob[0][1]:.2f}')
print(f'2번 품종일 확률 {y_prob[0][2]:.2f}')

728x90
반응형
'파이썬 > 머신러닝 및 딥러닝' 카테고리의 다른 글
| Python(Colab) 파이토치(Pytorch) + 딥러닝 해보기 (0) | 2023.06.20 |
|---|---|
| Python(Colab) 파이토치(Pytorch) + 데이터 로더 (2) | 2023.06.20 |
| Python(Colab) 파이토치(Pytorch) + 논리 회귀 (다항) (2) | 2023.06.20 |
| Python(Colab) 파이토치(Pytorch) + 논리 회귀 (0) | 2023.06.20 |
| Python(Colab) 파이토치(Pytorch) + 다항 선형회귀 해보기 (0) | 2023.06.20 |