Python(Colab) 전국 도시공원 데이터 주물럭거리기
2023. 6. 11. 19:19ㆍ실습 및 과제
1. 기초설정
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
2. 데이터 불러오기
park = pd.read_csv('/content/drive/MyDrive/KDT-1/데이터분석/전국도시공원표준데이터.csv',encoding='ms949')

3. 한글 사용 준비
설치 후 다시 런타임 시작!!
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
plt.rc('font',family='NanumBarunGothic')
4. 데이터 간단 조회
park.info()

5. 컬럼별 결측치 확인
park.isnull().sum()

6. 필요없는 컬럼 삭제하기
park.drop(columns=['공원보유시설(운동시설)', '공원보유시설(유희시설)',
'공원보유시설(편익시설)', '공원보유시설(교양시설)',
'공원보유시설(기타시설)','지정고시일', '관리기관명',
'Unnamed: 19'],inplace=True)
park.head()

7. 점 도표로 시각화 해보기 (조건: 위도,경도)
park.plot.scatter(x='경도',y='위도',figsize=(8,10),grid=True)
#데이터 + 점 도표 = x축 컬럼 , y축 컬럼 , 전체 표 사이즈, 격자(그리드)

8. 이상치 확인하기(boxplot) 위도
sns.boxplot(y=park['위도'])
# seaborn.boxplot (기준)

8-1. 이상치 확인하기(boxplot) 경도
sns.boxplot(y=park['경도'])
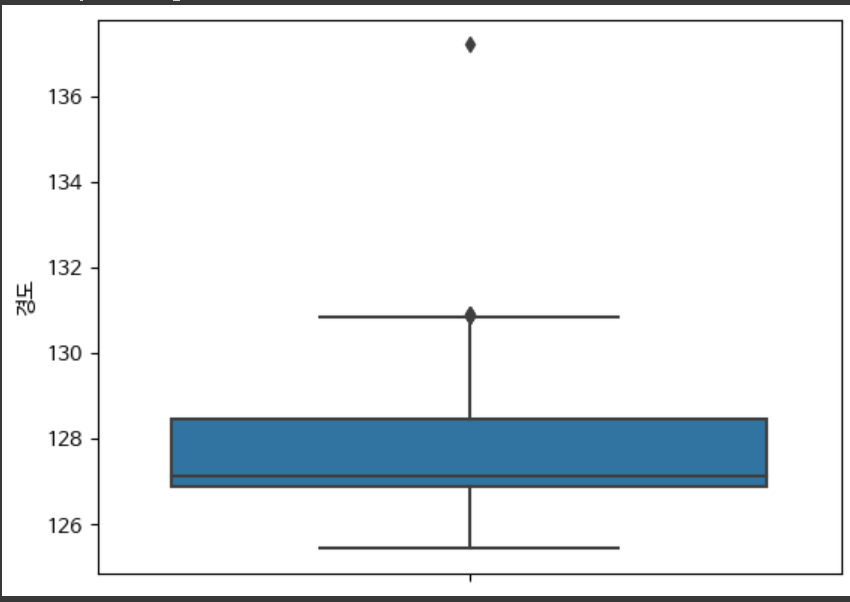
9. 위도, 경도가 잘못 입력된 데이터를 확인해서 다른 변수에 담아 둔다.
(주의점: park['위도']<32 라는 것은 시리즈가 출력되기 때문에 and와 or이 &,| 로 대체된다)
park.loc[(park['위도'] < 32) | (park['경도'] > 132)]
# park_loc_error 변수에 잘못된 데이터를 담아 둔다.
park_loc_error = park.loc[(park['위도'] < 32) | (park['경도'] > 132)]

10. 정상적인 데이터만 따로 분류(기준: 위도 경도가 대한민국 범주 안에 있는 것)
park = park.loc[(park['위도'] >= 32) & (park['경도'] <= 132)]
11. 파생변수 '공원면적비율' 만들기 (계산법: 공원면적의 제곱 * 0.01)
# 한번만 사용할 함수를 정의하기 위해 람다함수 적용
# numpy.sqrt = 제곱 하는 함수
park['공원면적비율'] = park['공원면적'].apply(lambda x : np.sqrt(x)* 0.01)

12. 연습) 도로명주소 X, 지번주소 O 데이터 찾기
#1. 도로명주소는 입력되지 않고, 지번 주소만 입력된 데이터만 확인
#2. 도로명주소 지번 주소 모두 입력된 데이터만 확인
#3. 도로명주소 지번 주소 모두 입력되지 않은 데이터만 확인
#도로명주소 모두 입력되지 않은 데이터를 지번 주소로 대신 채우자
#데이터 확인
park1 = park.loc[(park['소재지도로명주소'].isnull() == True) & (park['소재지지번주소'].notnull() == True )]
park1
park2 = park.loc[(park['소재지도로명주소'].notnull() == True) & (park['소재지지번주소'].notnull() == True )]
park2
park3 = park.loc[(park['소재지도로명주소'].isnull()) & (park['소재지지번주소'].isnull())]
park3
# 결측치 채우기
park1['소재지도로명주소'].fillna (park1['소재지지번주소'],inplace=True)
13. 소재지도로명주소를 분리시키기(기준: 띄어쓰기)
park1['소재지도로명주소'].str.split(' ',expand=True)
14. 소재지도로명주소에서 시도만 추출하여 '시도'파생변수를 만들기 (추후 seaborn 표 중 hue로 사용할 예정)
park['시도'] = park['소재지지번주소'].str.split(' ',expand=True)[0]

15. '시도'컬럼 중 "강원" -> "강원도"로 변경
park['시도'][park['시도']=='강원'] = '강원도'
16. '시도'를 hue를 사용하여 시각화하기
plt.figure(figsize=(8,10))
sns.scatterplot(data=park, x='경도',y='위도',hue='시도')
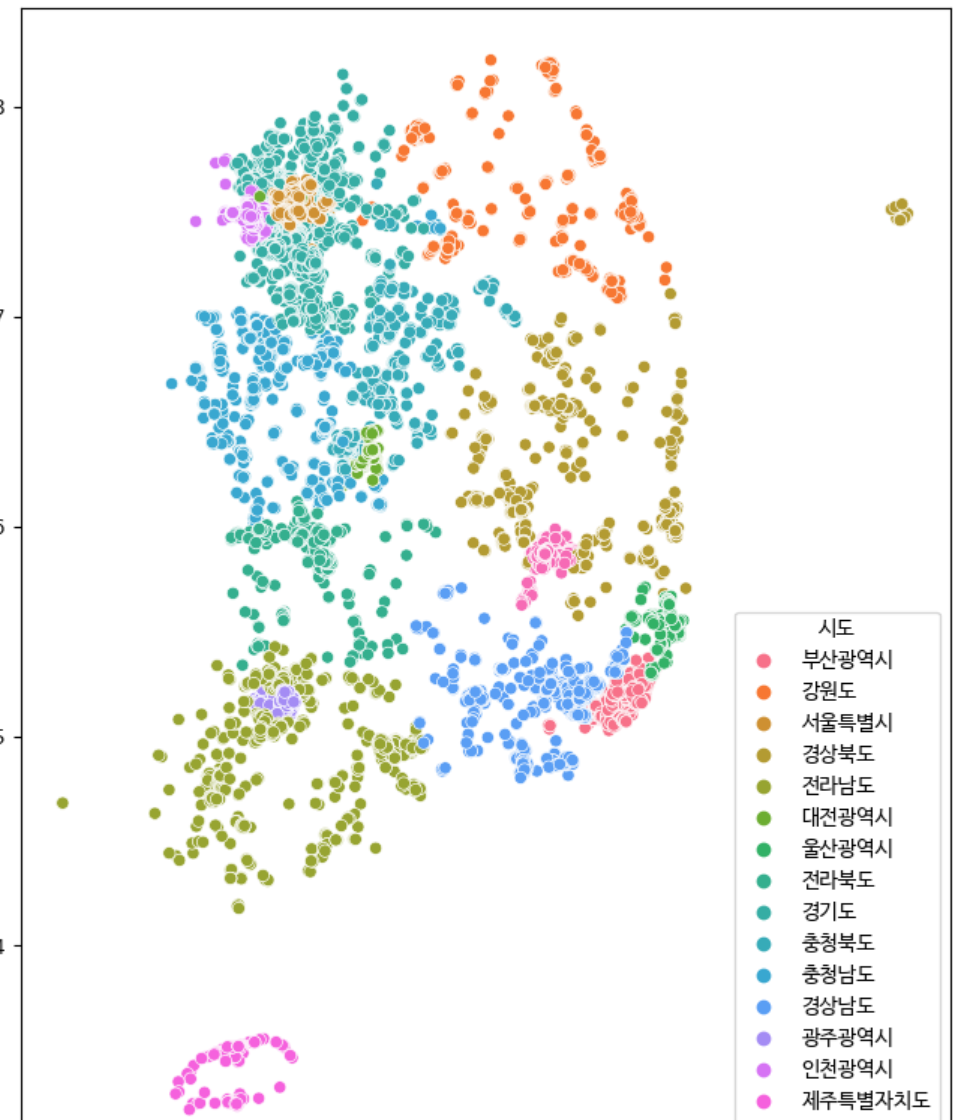
17. '시도'를 다른 데이터 프레임으로 만들기
park_sido = pd.DataFrame(park['시도'].value_counts())

🟡17. '시도'의 value를 비율로 확인하기
# value_counts(nomalize=True): 전체 합계에 대한 비율이 계산
park_sido_normalize = pd.DataFrame(park['시도'].value_counts(normalize=True))
park_sido_normalize

728x90
반응형
'실습 및 과제' 카테고리의 다른 글
| Python(Colab) 상권 별 업종 밀집 통계 주물럭거리기 (0) | 2023.06.09 |
|---|---|
| JavaScripts _ 기초 간단 프로그램(성인 구별) (0) | 2023.04.05 |
| CSS+VSCODE 카페 메인 페이지 만들기 (0) | 2023.04.04 |